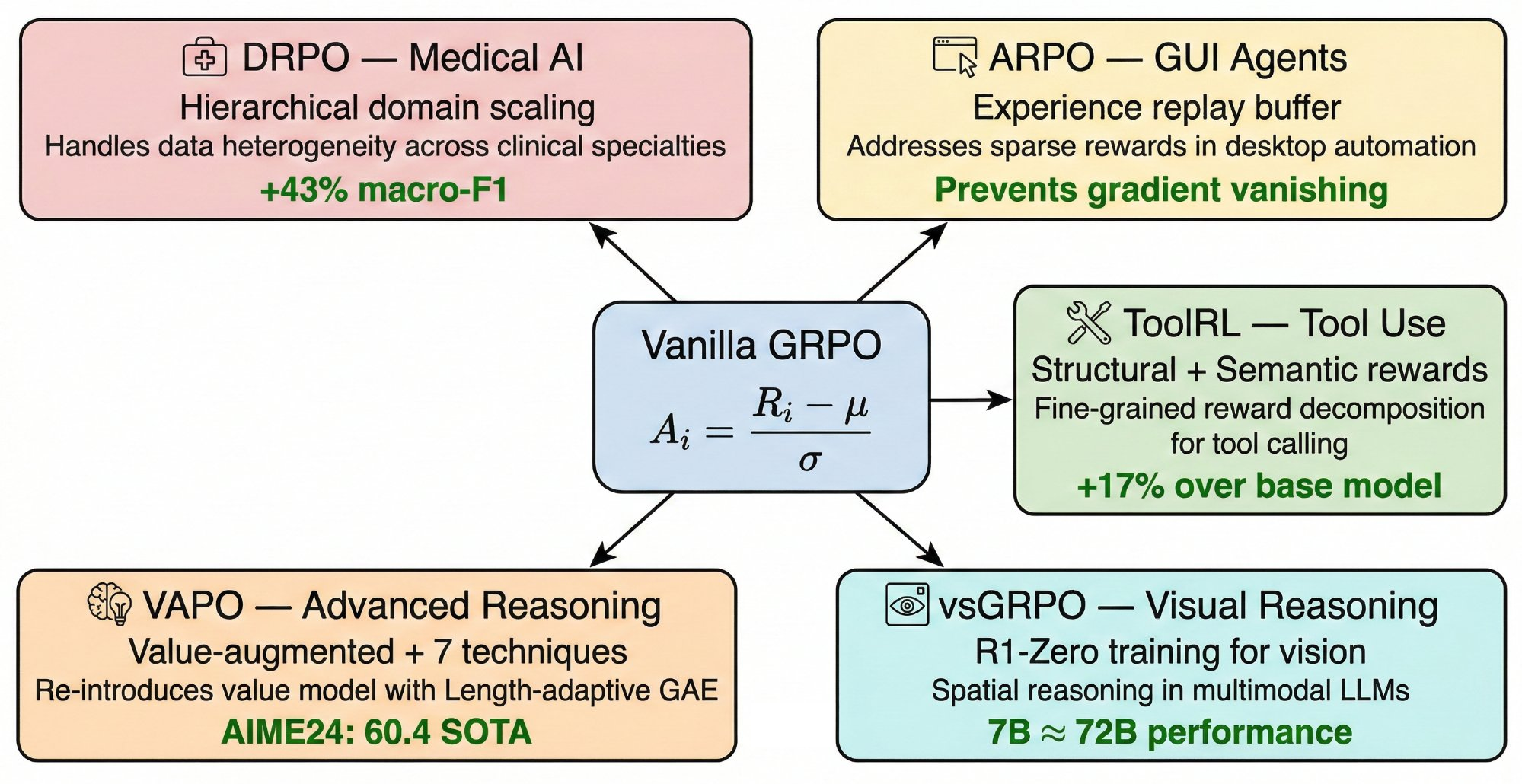
Evolution of GRPO Variants
From DeepSeekMath (2024.02) to 20+ variants across six research directions
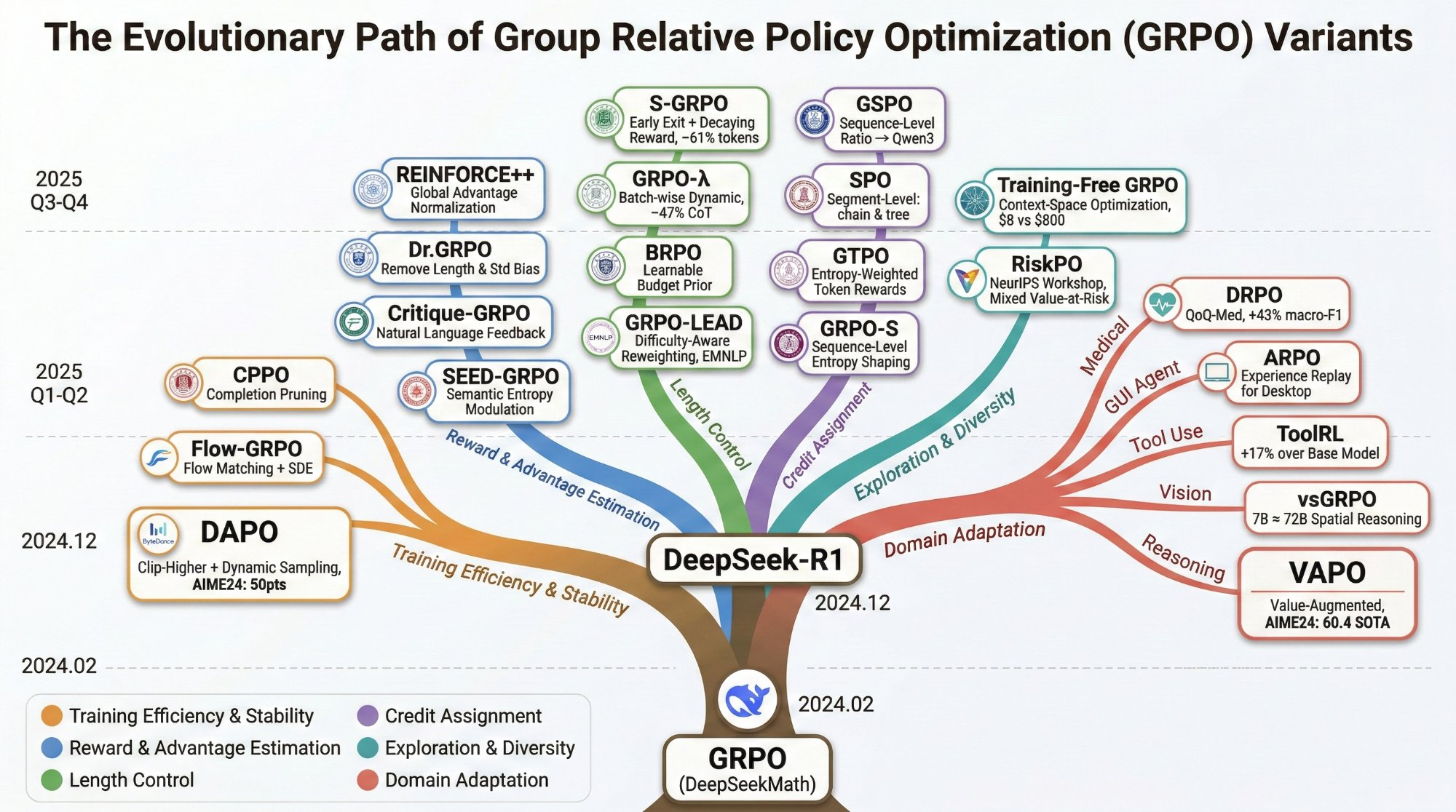
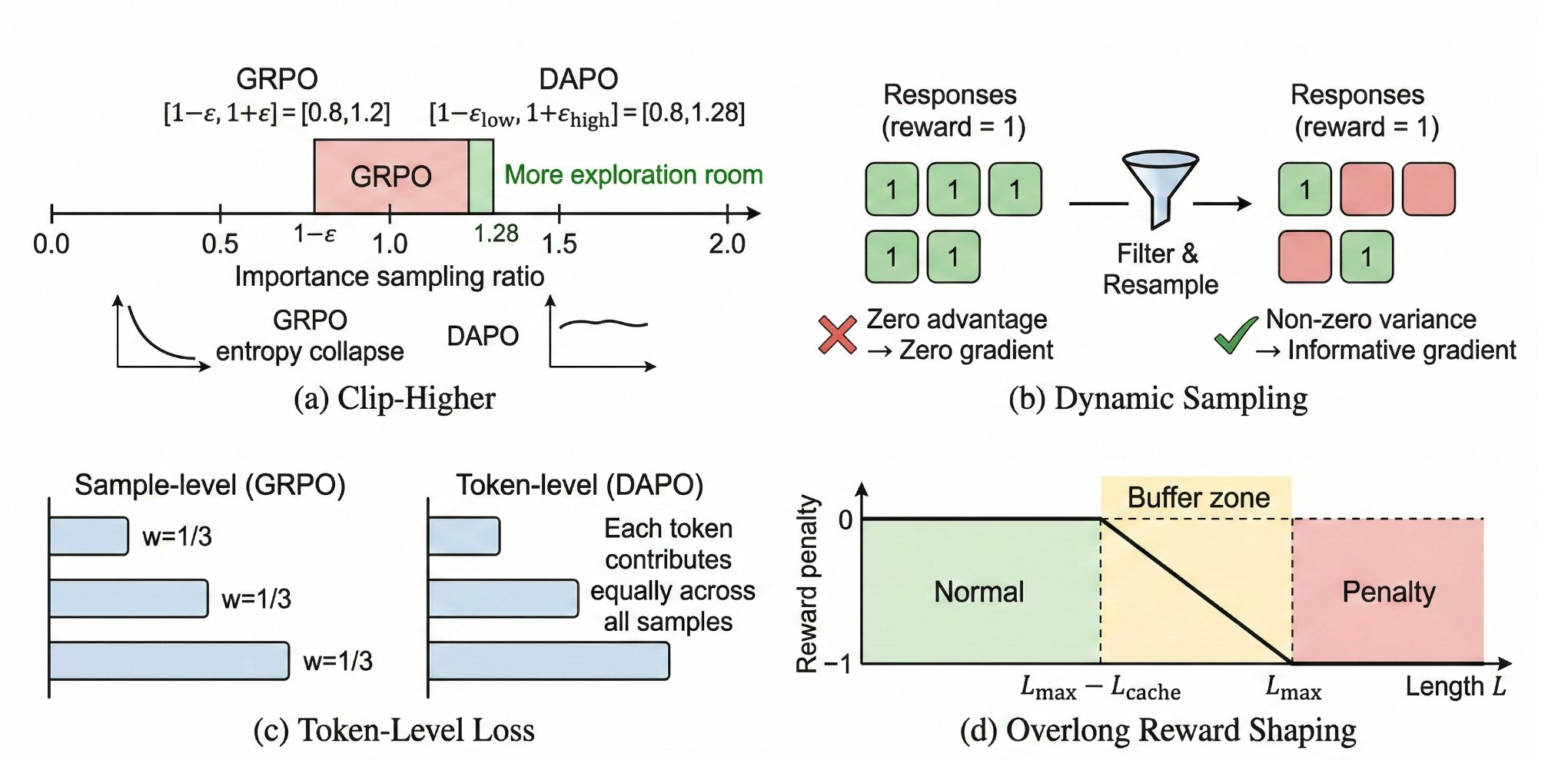
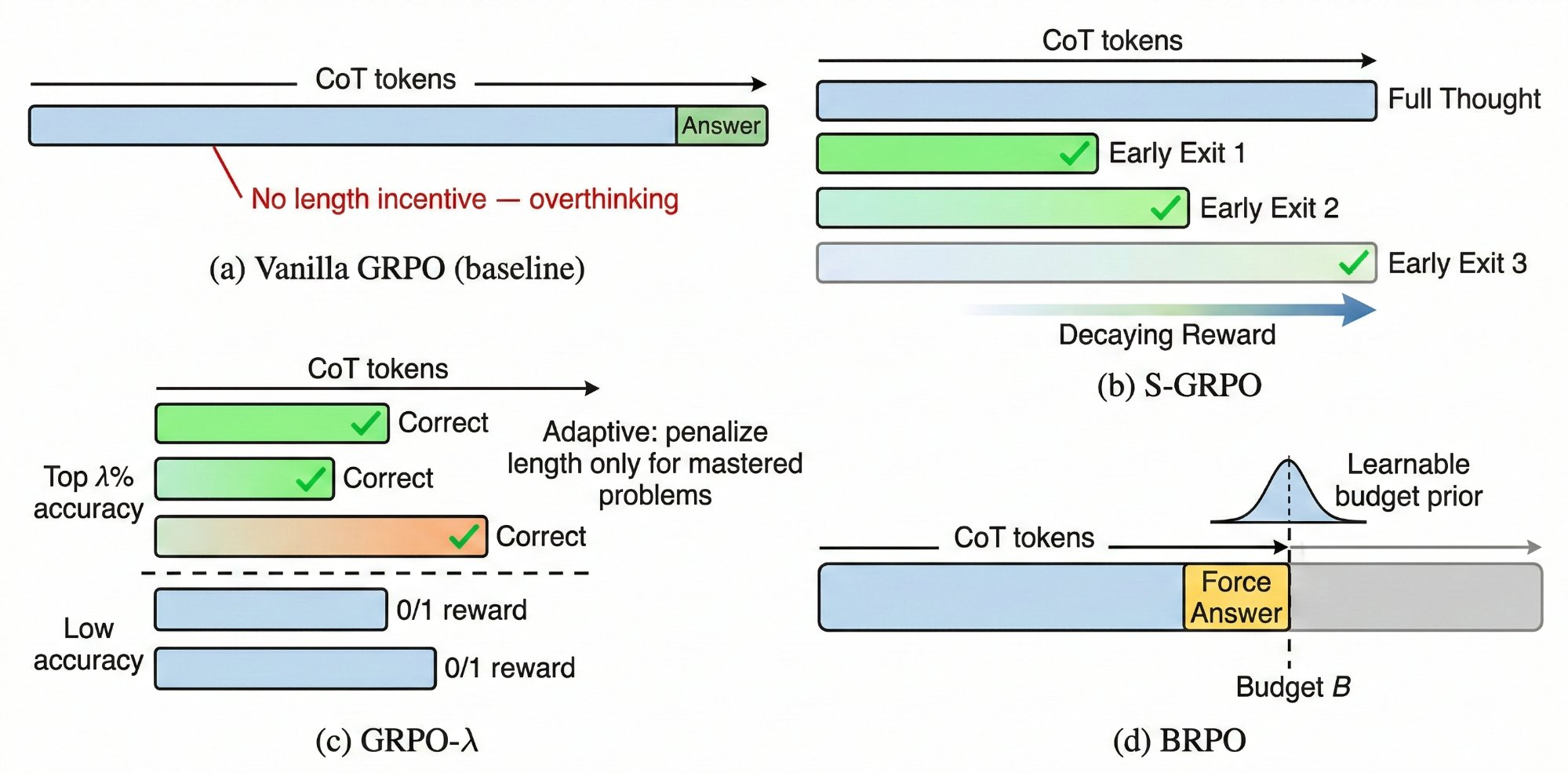
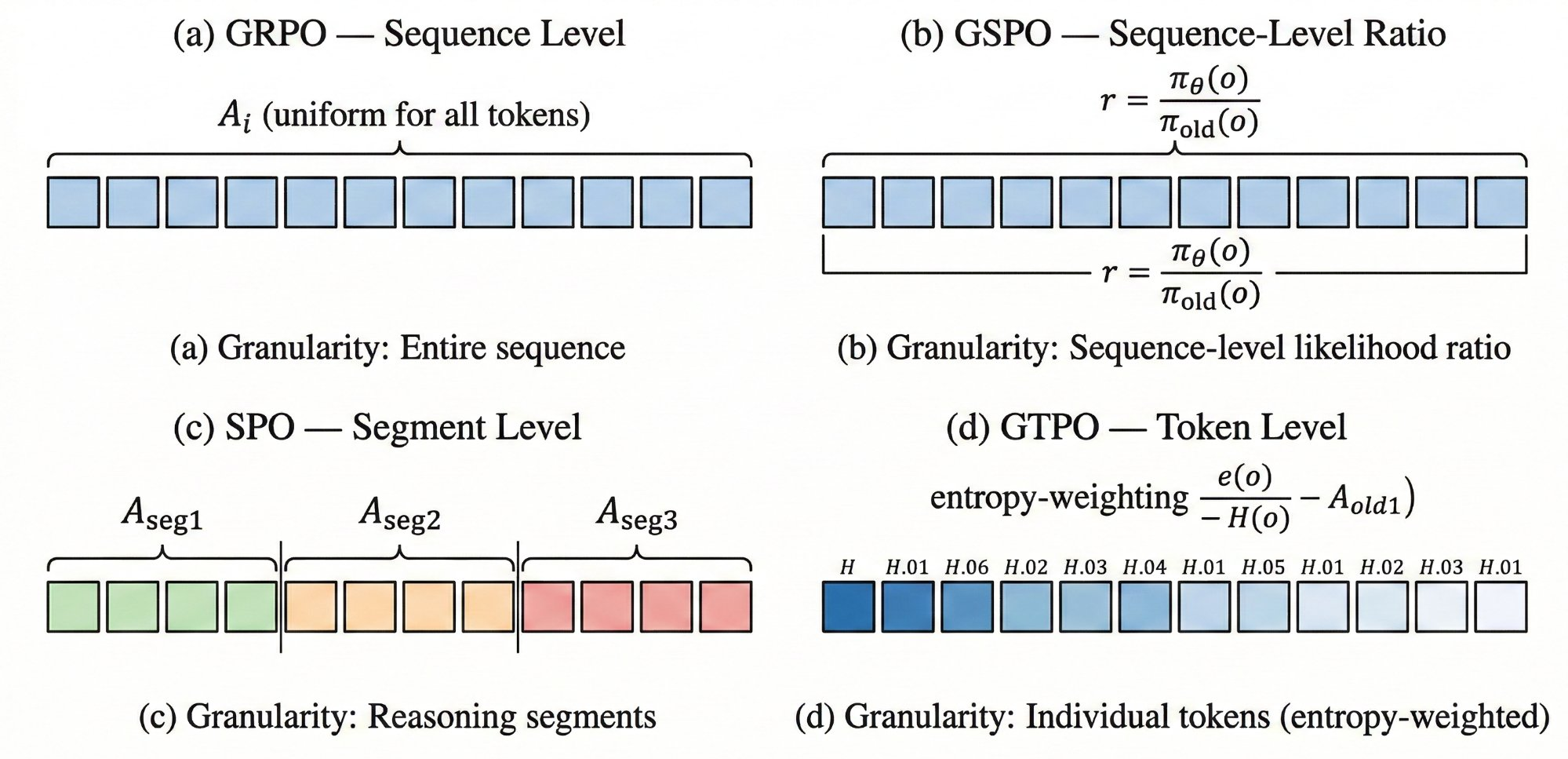
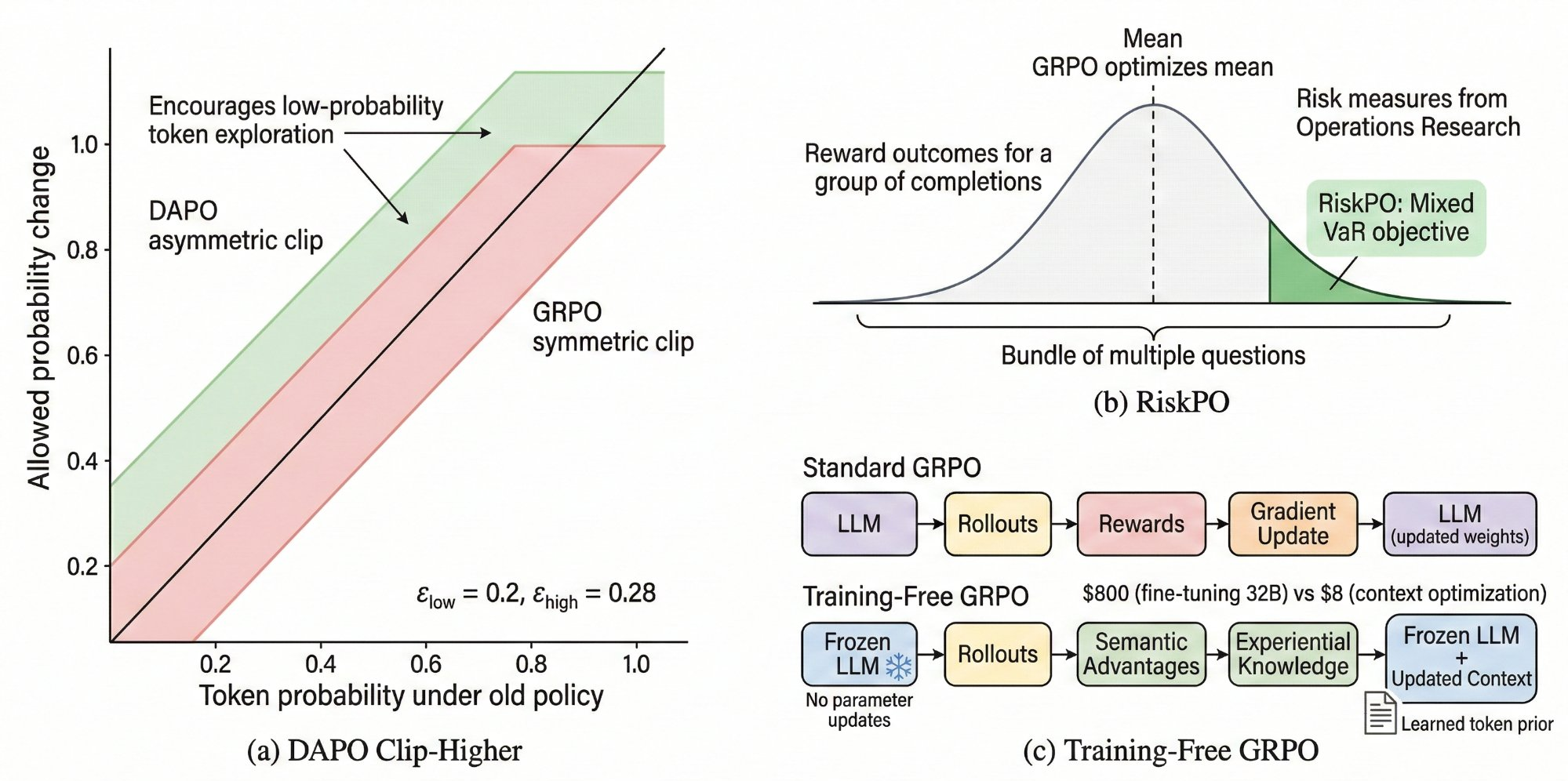
Figure 1. The evolutionary path of GRPO variants. Branches cover training efficiency (orange), reward/advantage estimation (blue), length control (green), credit assignment (purple), exploration (teal), and domain adaptation (red).